SK 광 인터넷을 설치 하는 경우를 예를 들어 보면, 기사가 와서 아래 것들을 설치해 주고 간다.
1. 모뎀
2. 유무선 공유기
3. Nugu 스마트 스피커
이 중 스마트 스피커는 인터넷을 하는 것과 상관이 없고... 실제로는 모뎀과 공유기가 기능을 담당한다.
모뎀
1. 정의
정보 전달(주로 디지털 정보)을 위해 신호를 변조하여 송신하고 수신측에서 원래의 신호로 복구하기 위해 복조하는 장치를 말한다. 주로 컴퓨터 정보통신을 위한 주변기기로 많이 사용한다. 변조를 하는 이유는 전송선에 디지털 신호를 바로 보내면 신호 전달이 잘 되지 않기 때문이다. 데이터가 같은 비트로 연속되면 전송특성상 신호 전달에 문제가 발생하므로 전송선의 특성에 맞추어 변조한다.
모뎀은 아날로그/디지털 변환기의 일종으로 컴퓨터의 디지털 신호를 아날로그 신호로 바꾸어 전송하고, 아날로그 신호를 받아 디지털 신호로 읽어낸다. 좁은 의미에서는 개인용 컴퓨터와 전화선을 이어주는 주변기기이다.
2. 실제
SK 광 인터넷이 모뎀으로 연결된다. (가정 또는 사무실 네트워크로 유입되는 인터넷 트래픽의 첫 번째 연락 지점이다.)
모뎀은 동축 케이블 또는 전화 케이블, 또는 광 케이블을 사용하여 인터넷 서비스 제공 업체의 네트워크에 연결한다.
즉 모뎀을 통해 SK 인터넷 망을 이용할 수 있게 된다.
공유기
1. 정의
Home Router. 가정용 및 소기업에서 사용하는 소용량라우터를 말한다. 기기에 따라서는Wi-Fi칩셋과 안테나를 더해AP기능까지 하기도 한다.
공유기의 가장 기본적인 기능은ISP(인터넷 회사)에서 할당해 주는 하나의IP를 이용하여 여러 대의컴퓨터가인터넷에 접속할 수 있도록 해 주는 것이다. 한편, 여러 대의컴퓨터에서인터넷을 사용하려면 ISP에서 공인IP주소를 여러 개 할당받는 게 원칙이다. 그런데 ISP에서는 추가 IP마다 돈을 내도록 강요하기 때문에, 'IP를 하나만 사용해서 여러 대 컴퓨터가 인터넷을 할 수 없을까'라는 고민 끝에,라우터의 NAT 기능과게이트웨이, 허브 및 네트워크 관리 도구를 통합하여 나온 물건이 인터넷 공유기이다.
2. 실제
공유기로 사설 로컬 네트워크(LAN)을 구성하여 여러 컴퓨터에서 인터넷 접속이 가능하도록 해준다.
모뎀이 공유기에 연결 되어 있고, 공유기에 컴퓨터가 연결(무선 또는 유선) 되어 인터넷 사용이 가능해진다.
즉, 집안의 컴퓨터나 휴대폰은 허브 역할을 하는 공유기에 접속해 사설 IP를 할당받아 사용하게 되고, 공유기는 모뎀에 연결되어 모뎀에 부여된 IP로 네트워크에 연결이 된다. (공유기가 LAN과 WAN 사이의 중계역할을 한다.)
사업, 교육, 정부 기관들은 광역 통신망을 사용하여 세계의 다양한 지역의 직원, 학생, 고객, 구매자, 공급자에게 데이터를 중계한다. 본질적으로 이러한 방식의 전기통신은 장소에 관계없이 날마다 비즈니스가 효율적으로 수행될 수 있도록 도와준다.인터넷은 광역 통신망으로 간주될 수 있다.[2]
그 밖의 관련 통신망은 영역에 의해 구분되는데,개인 통신망(PAN : 방 단위),근거리 통신망(LAN : 건물 단위),캠퍼스 통신망(CAN : 캠퍼스 단위),도시권 통신망(MAN : 도시 단위)이 있다.
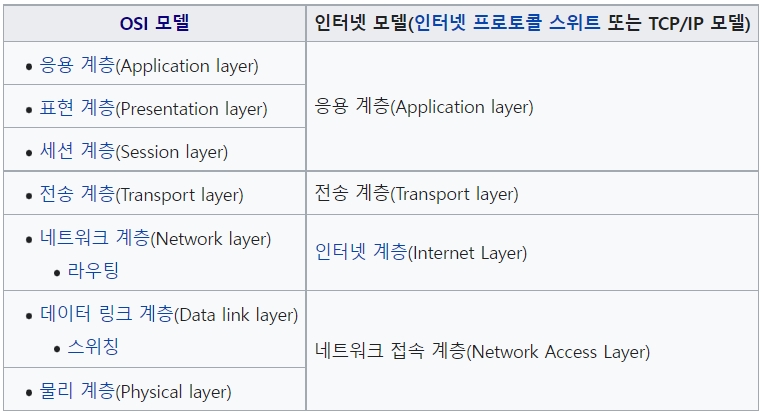
OSI 7계층 (OSI 모형, Open Systems Interconnection Reference Model)
국제표준화기구(ISO)에서 개발한 모델로, 컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명한 것이다. 일반적으로OSI 7 계층이라고 한다.
목적
이 모델은 프로토콜을 기능별로 나눈 것이다. 각 계층은 하위 계층의 기능만을 이용하고, 상위 계층에게 기능을 제공한다. '프로토콜 스택' 혹은 '스택'은 이러한 계층들로 구성되는 프로토콜 시스템이 구현된 시스템을 가리키는데, 프로토콜 스택은 하드웨어나 소프트웨어 혹은 둘의 혼합으로 구현될 수 있다. 일반적으로 하위 계층들은 하드웨어로, 상위 계층들은 소프트웨어로 구현된다.
계층 기능
계층 1: 물리 계층
물리 계층(Physical layer)은 네트워크의 기본 네트워크 하드웨어 전송 기술을 이룬다. 네트워크의 높은 수준의 기능의 논리 데이터 구조를 기초로 하는 필수 계층이다. 다양한 특징의 하드웨어 기술이 접목되어 있기에 OSI 아키텍처에서 가장 복잡한 계층으로 간주된다.
계층 2: 데이터 링크 계층
데이터 링크 계층(Data[3]link layer)은 포인트 투 포인트(Point to Point) 간 신뢰성있는 전송을 보장하기 위한 계층으로 CRC 기반의 오류 제어와 흐름 제어가 필요하다. 네트워크 위의 개체들 간데이터를 전달하고, 물리 계층에서 발생할 수 있는 오류를 찾아 내고, 수정하는 데 필요한 기능적, 절차적 수단을 제공한다. 주소 값은 물리적으로 할당 받는데, 이는 네트워크 카드가 만들어질 때부터 맥 주소(MAC address)가 정해져 있다는 뜻이다. 주소 체계는 계층이 없는 단일 구조이다. 데이터 링크 계층의 가장 잘 알려진 예는이더넷이다.
프레임에 주소부여(MAC - 물리적주소)
에러검출/재전송/흐름제어
계층 3: 네트워크 계층
네트워크 계층(Network layer)은 여러개의 노드를 거칠때마다 경로를 찾아주는 역할을 하는 계층으로 다양한 길이의데이터를 네트워크들을 통해 전달하고, 그 과정에서 전송 계층이 요구하는서비스 품질(QoS)을 제공하기 위한 기능적, 절차적 수단을 제공한다. 네트워크 계층은 라우팅, 흐름 제어, 세그멘테이션(segmentation/desegmentation), 오류 제어, 인터네트워킹(Internetworking) 등을 수행한다. 라우터가 이 계층에서 동작하고 이 계층에서 동작하는 스위치도 있다. 데이터를 연결하는 다른 네트워크를 통해 전달함으로써 인터넷이 가능하게 만드는 계층이다. 논리적인 주소 구조(IP), 곧 네트워크 관리자가 직접 주소를 할당하는 구조를 가지며, 계층적(hierarchical)이다.
주소부여(IP)
경로설정(Route)
계층 4: 전송 계층
전송 계층(Transport layer)은 양 끝단(End to end)의 사용자들이 신뢰성있는데이터를 주고 받을 수 있도록 해 주어, 상위 계층들이 데이터 전달의 유효성이나 효율성을 생각하지 않도록 해준다. 시퀀스 넘버 기반의 오류 제어 방식을 사용한다. 전송 계층은 특정 연결의 유효성을 제어하고, 일부 프로토콜은 상태 개념이 있고(stateful), 연결 기반(connection oriented)이다. 이는 전송 계층이 패킷들의 전송이 유효한지 확인하고 전송 실패한 패킷들을 다시 전송한다는 것을 뜻한다. 가장 잘 알려진 전송 계층의 예는TCP이다.
종단간(end-to-end) 통신을 다루는 최하위 계층으로 종단간 신뢰성 있고 효율적인 데이터를 전송하며, 기능은 오류검출 및 복구와 흐름제어, 중복검사 등을 수행한다.
세션 계층(Session layer)은 양 끝단의 응용 프로세스가 통신을 관리하기 위한 방법을 제공한다. 동시 송수신 방식(duplex), 반이중 방식(half-duplex), 전이중 방식(Full Duplex)의 통신과 함께, 체크 포인팅과 유휴, 종료, 다시 시작 과정 등을 수행한다. 이 계층은 TCP/IP 세션을 만들고 없애는 책임을 진다.
통신하는 사용자들을 동기화하고 오류복구 명령들을 일괄적으로 다룬다.
통신을 하기 위한 세션을 확립/유지/중단 (운영체제가 해줌)
계층 6: 표현 계층
표현 계층(Presentation layer)은 코드 간의 번역을 담당하여 사용자 시스템에서데이터의 형식상 차이를 다루는 부담을 응용 계층으로부터 덜어 준다.MIME인코딩이나 암호화 등의 동작이 이 계층에서 이루어진다. 예를 들면,EBCDIC로 인코딩된 문서파일을ASCII로 인코딩된 파일로 바꿔 주는 것이 표현 계층의 몫이다.
사용자의 명령어를 완성및 결과 표현.
포장/압축/암호화
계층 7: 응용 계층
응용 계층(Application layer)은 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행한다. 일반적인 응용 서비스는 관련된 응용 프로세스들 사이의 전환을 제공한다. 응용 서비스의 예로, 가상 터미널(예를 들어,텔넷), FTP 등이 있다.
리눅스, 특히 CentOS7 에서는 rsyslog라는 로그 시스템이 다양한 로그를 남긴다.
또한 로그가 계속 쌓이면 파일 사이즈가 비대해져 디스크 공간 부족이 생길 수 있고, 파일을 열어 분석하는 작업도 쉽지 않기에, logrotate라는 프로그램이 쌓인 로그를 파일로 분할하고, 오래된 로그 파일을 삭제하는 등의 작업을 한다.
rsyslog
시스템의 다양한 로그를 남긴다
1. 로그 파일 저장 위치 : /var/log/ 디렉토리 하위에 저장
2. 주요 로그파일
로그파일
설명
messages
인증, 메일, cron을 제외한 대부분의 로그가 기록되는 파일
secure
인증, 즉 보안 관련 로그가 저장되는 파일
maillog
메일 관련 모든 로그가 저장되는 파일
cron
cron 관련 모든 로그가 저장되는 파일
spooler
uucp, news의 심각한 로그가 저장되는 파일
boot.log
부팅 메시지가 저장된 로그 파일
3. rsyslog 운영
rsyslog 시작
# systemctl start rsyslog
rsyslog 재시작
# systemctl restart rsyslog
rsyslog 종료
# systemctl stop rsyslog
rsyslog 상태확인
# systemctl status rsyslog
logrotate (로그로테이트)
쌓인 로그를 파일로 분할하고, 오래된 로그 파일을 삭제하는 등의 작업을 하여 로그를 관리한다.
파일을 어떻게 분할할지, 어떤 주기로 로테이트 시킬지 등은 logrotate 설정에서 가능하다.
1. logrotate 설정 : /etc/logrotate.conf
2. logrotate 설정파일 보기/수정하기
아래 명령어로 설정파일을 열어보고, 수정 후 저장하면 된다.
# vi /etc/logrotate.conf
logrotate.conf 내용 예
: 매주 로테이트, 최대 4개의 과거 로그 보관, 로그 파일 사이즈가 10M 이상이 되면 로테이트, 로그파일 압축 보관하는 예이다.
# see "man logrotate" for details
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
size 10M
# create new (empty) log files after rotating old ones
create
# use date as a suffix of the rotated file
dateext
# uncomment this if you want your log files compressed
compress
# RPM packages drop log rotation information into this directory
include /etc/logrotate.d
# no packages own wtmp and btmp -- we'll rotate them here
/var/log/wtmp {
monthly
create 0664 root utmp
minsize 1M
rotate 1
}
/var/log/btmp {
missingok
monthly
create 0600 root utmp
rotate 1
}
# system-specific logs may be also be configured here.